Towards Addressing GAN Training Instabilities: Dual-Objective GANs with Tunable Parameters 🎛 🤏
Robust Generative Models, Convolutional Nets, Fréchet Inception Distance
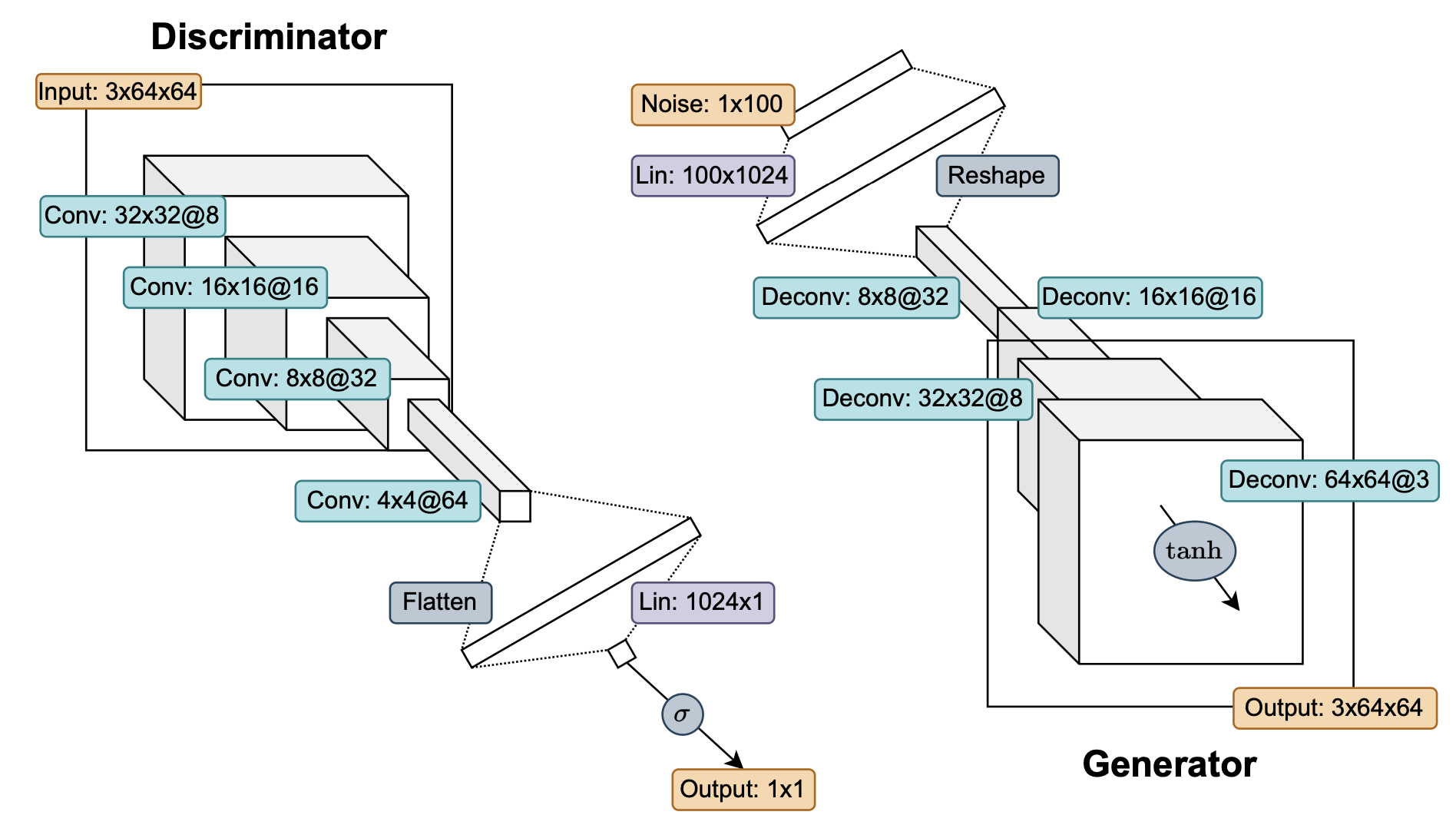
This thesis introduces the \((\alpha_{D}, \alpha_{G})\)-GAN, a parameterized class of dual-objective GANs, as an alternative approach to the standard vanilla GAN.
The \((\alpha_{D}, \alpha_{G})\)-GAN formulation, inspired by \(\alpha\)-loss, allows practitioners to tune the parameters \((\alpha_{D}, \alpha_{G}) \in [0,\infty)^{2}\) to provide a more stable training process. The objectives for the generator and discriminator in \((\alpha_{D}, \alpha_{G})\)-GAN are derived, and the advantages of using these objectives are investigated. In particular, the optimization trajectory of the generator is found to be influenced by the choice of \(\alpha_{D}\) and \(\alpha_{G}\).
Empirical evidence is presented through experiments conducted on various datasets, including the 2D Gaussian Mixture Ring, Celeb-A image dataset, and LSUN Classroom image dataset. Performance metrics such as mode coverage and Fréchet Inception Distance (FID) are used to evaluate the effectiveness of the \((\alpha_{D}, \alpha_{G})\)-GAN compared to the vanilla GAN and state-of-the-art Least Squares GAN (LSGAN). The experimental results demonstrate that tuning \(\alpha_{D} < 1\) leads to improved stability, robustness to hyperparameter choice, and competitive performance compared to LSGAN.
Paper · Presentation · Github
February 2023 - June 2023
\((\alpha_{D}, \alpha_{G})\)-GANs: ✌ ✅ Addressing GAN Training Instabilities via Dual Objectives
Robust Generative Models, Convolutional Nets, Fréchet Inception Distance
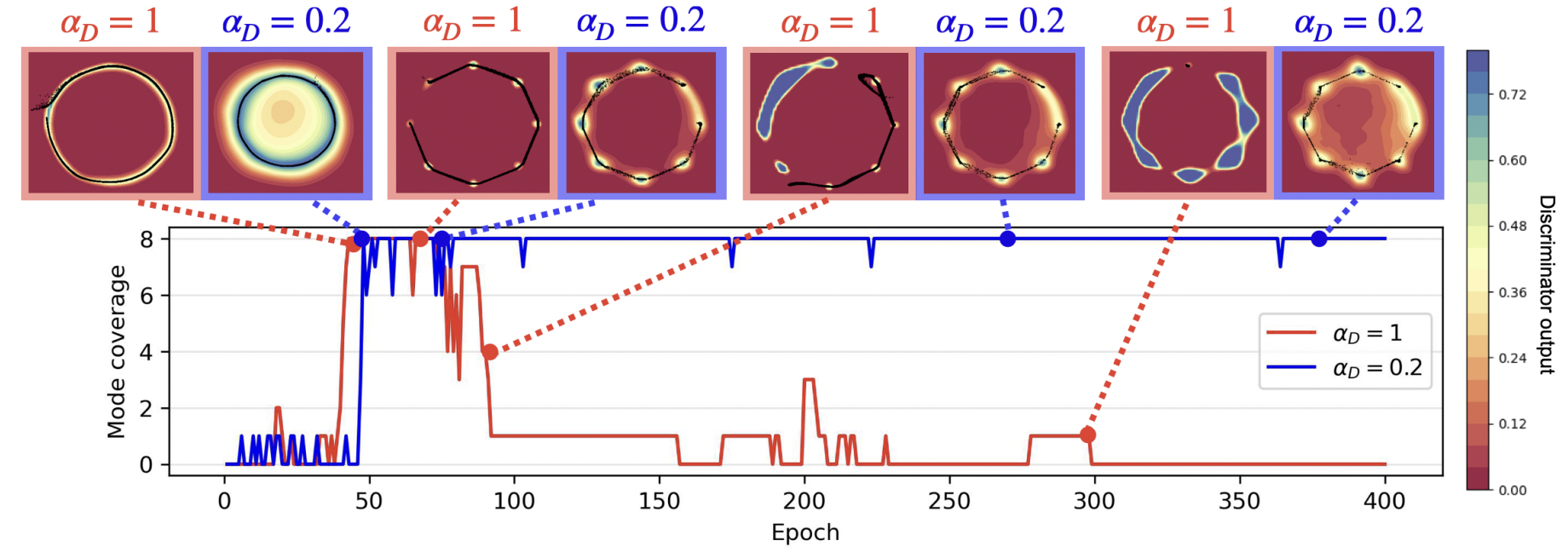
In an effort to address the training instabilities of GANs, we introduce a class of dual-objective GANs with different value functions (objectives) for the generator (\(G\)) and discriminator (\(D\)).
In particular, we model each objective using \(\alpha\)-loss, a tunable classification loss, to obtain \((\alpha_{D}, \alpha_{G})\)-GANs, parameterized by \((\alpha_{D}, \alpha_{G}) \in [0, \infty)^{2}\).
For sufficiently large number of samples and capacities for \(G\) and \(D\), we show that the resulting non-zero sum game simplifies to minimizing an \(f\)-divergence under appropriate conditions on \((\alpha_{D}, \alpha_{G})\).
In the finite sample and capacity setting, we define estimation error to quantify the gap in the generator's performance relative to the optimal setting with infinite samples and obtain upper bounds on this error, showing it to be order optimal under certain conditions.
Finally, we highlight the value of tuning \((\alpha_{D}, \alpha_{G})\) in alleviating training instabilities for the synthetic 2D Gaussian mixture ring and the Stacked MNIST datasets.
Paper · Poster · Github
November 2022 - January 2023
DiscoNet: 🕺 🕸 Towards Mitigating Shortcut Learning with Cross-Domain Regularization
Domain Adaptation, Shortcut Learning, Generative Adversarial nets
Deep learning methods have achieved remarkable advancements in the task of image classification, but progress has been particularly limited in settings of out-of-distribution testing.
As a result, domain adaptation methods have been proposed to robustify the model against unforeseen data distribution shifts; however, we find that these methods are inherently vulnerable to
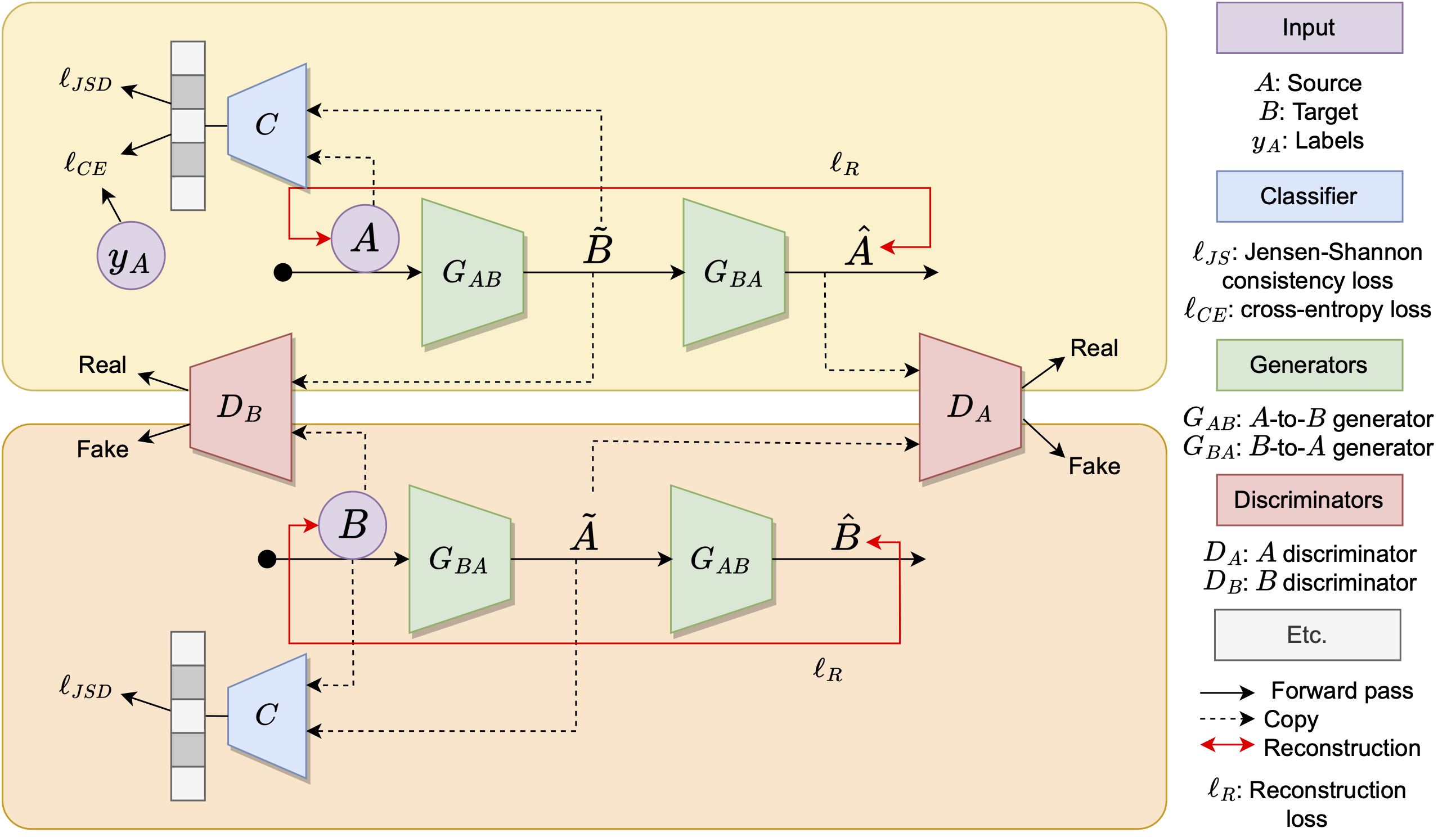
shortcut learning, a phenomenon where models learn on spurious cues instead of the true image semantics. In this project, we propose a new domain adaptation method, DiscoNet, that learns
a cross-domain mapping between the source and target domains in order to embed each dataset similarly during training. We find that our approach is robust to shortcut learning, which is demonstrated with our
novel dataset called Striped MNIST. Overall, we hope to underscore the importance of finding a relationship between source and target datasets when curating new domain adaptation solutions.
Paper · Github
October 2022 - December 2022
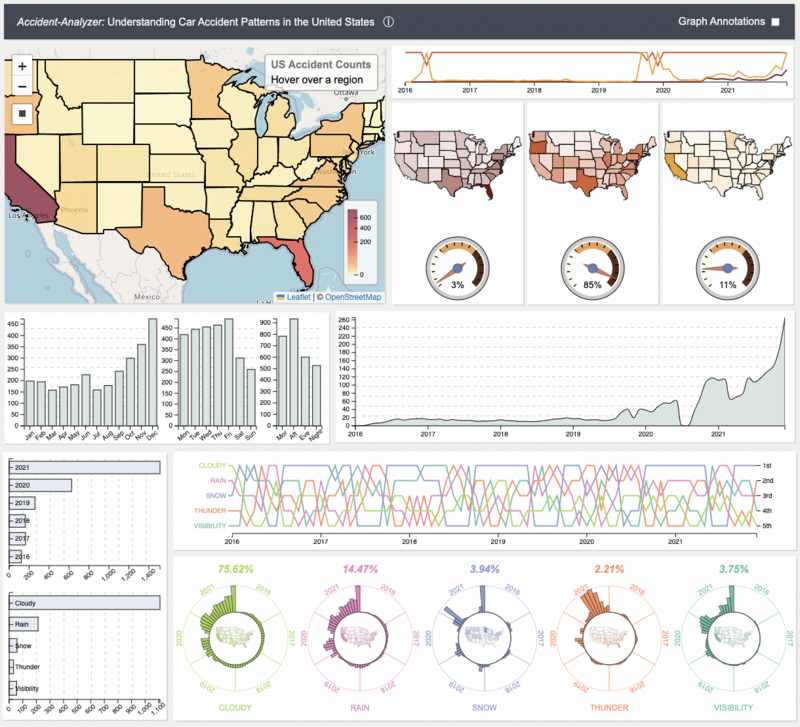
Accident-Analyzer: 🚗 🗺 Understanding Vehicle Accident Patterns in the United States
Data Visualization, D3 Javascript library
In this project, we re-imagine CrimAnalyzer- a visualization assisted analytic tool for crimes in São Paulo- in the context of traffic accidents, ultimately producing Accident-Analyzer. In doing so, we explore the spatio-temporal patterns of traffic accidents across the United States from 2016 to 2021. The Accident-Analyzer system allows for users to identify local hotspots, visualize accident trends over time, and filter the data by key weather categories in real-time. The visualization was primarily created with the D3 and Leaflet JS libraries, the dataset preprocessing was done with Python, and the data is stored/accessed via MySQL database.
Paper · Poster · Github
September 2022 - December 2022
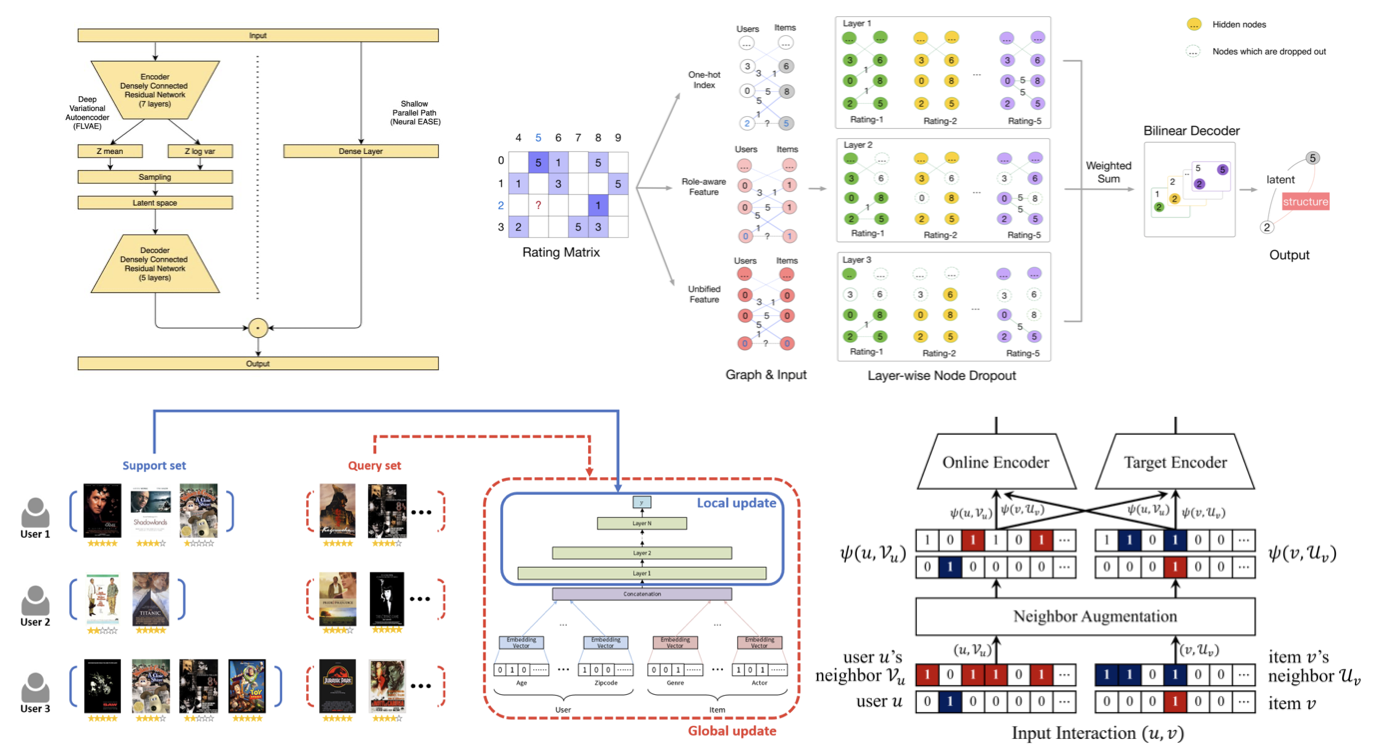
A Survey of Deep Learning-Based Movie Recommendation Systems 🎬
Recommendation Systems, Deep Learning
In this work, we provide a comprehensive and systematic analysis of current research methods on deep learning-based movie recommendation systems, specifically with empirical evaluation on the benchmark MovieLens dataset. We also provide a detailed taxonomy and summaries of state-of-the-art algorithms, providing a perspective on the future trends and research challenges of deep learning recommendation systems.
Paper · Presentation · Github
September 2022 - December 2022

Non-Targeted White-Box Evasion Attacks on the Fashion MNIST dataset 🔐👗
Adversarial learning, evasion attacks, deep learning
In this project, I train a convolutional neural net (CNN) with a LeNet-5 architecture on the Fashion MNIST dataset, which achieves a 99.3% validation accuracy. Then, I implement two white-box evasion attacks– namely, fast gradient sign method (FGSM) and projected gradient descent (PGD)– in order to create adversarial examples that closely resemble the original Fashion MNIST image, yet dramatically alter the classification output of the CNN. This project underscores the vulnerability of the standard deep learning classification algorithm to carefully-crafted adversarial images.
Report · Github
September 2022 - September 2022
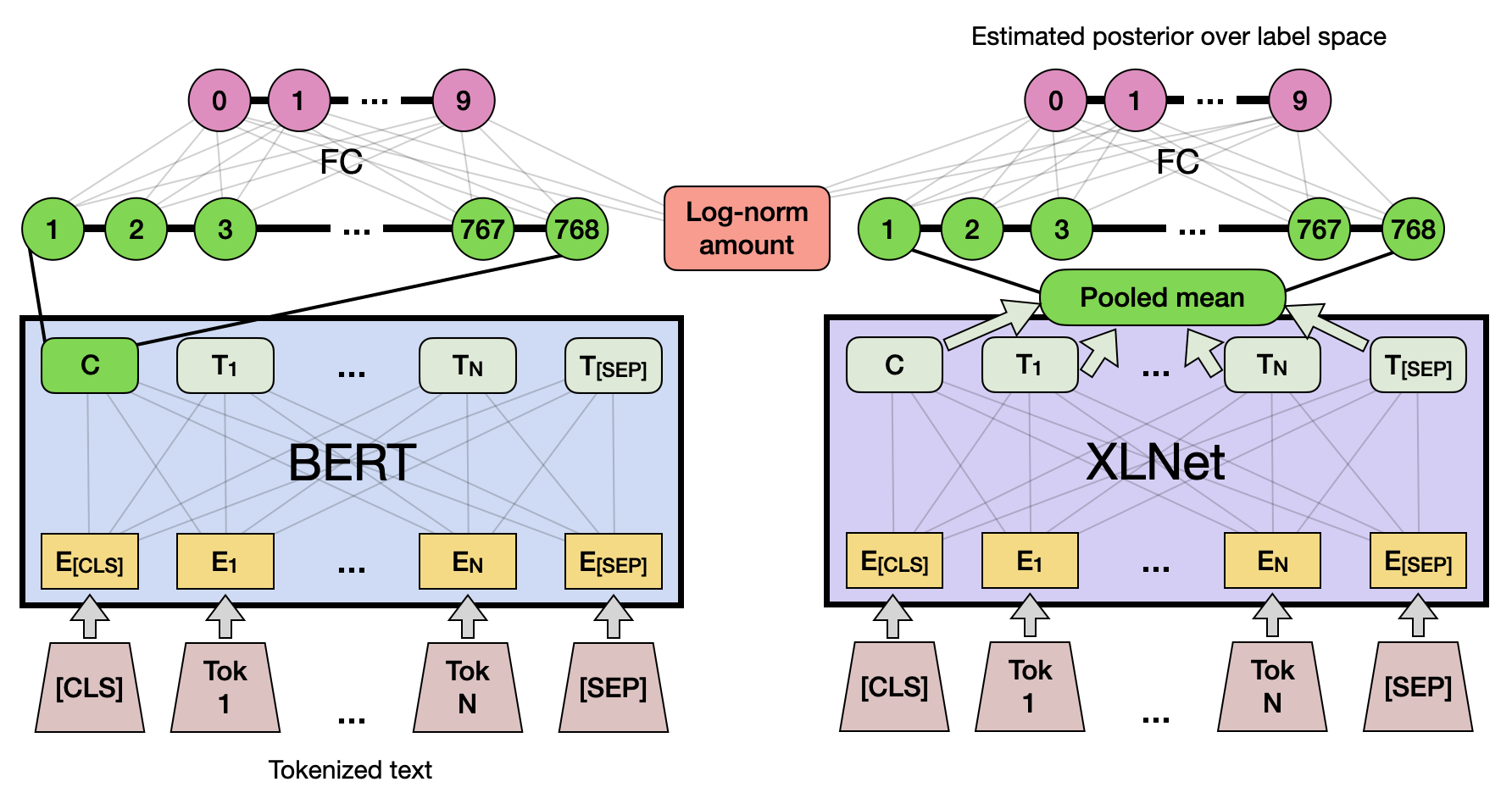
Building Robust and Accurate Transaction Classifiers with Deep Transfer Learning 💰✅
NLP, Gradient Boosting, Deep Transformers, Web Scraping
In this work, I develop a solution for the task of transaction categorization, specifically with the
dataset provided by the 2022 Wells Fargo Campus Analytics Challenge. Overall, I achieve a few
noteworthy contributions, including the engineering of two attributes responsible for improvement
in ML performance, development of a word clustering algorithm that helps the practitioner better understand the relationships between words across categories, and design of a high-performing
classifier of 88% test accuracy using deep transfer learning and state-of-the-art optimization techniques.
Paper · Github
June 2022 - July 2022
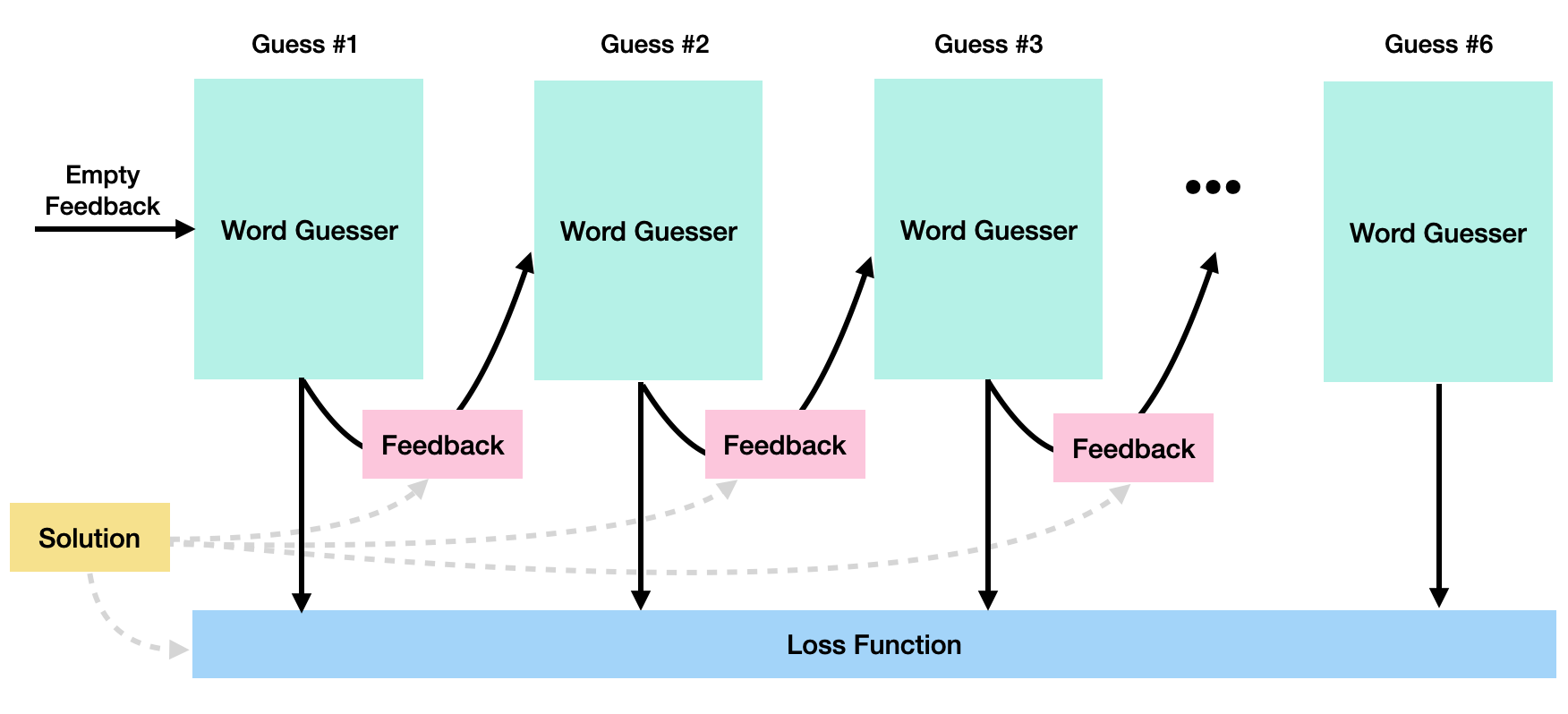
WordleNet: 📱 Training a Recurrent Neural Network to Play the game "Wordle"
Recurrent Neural Nets, Deep Learning
Article (Coming soon) · Github
June 2022 - June 2022
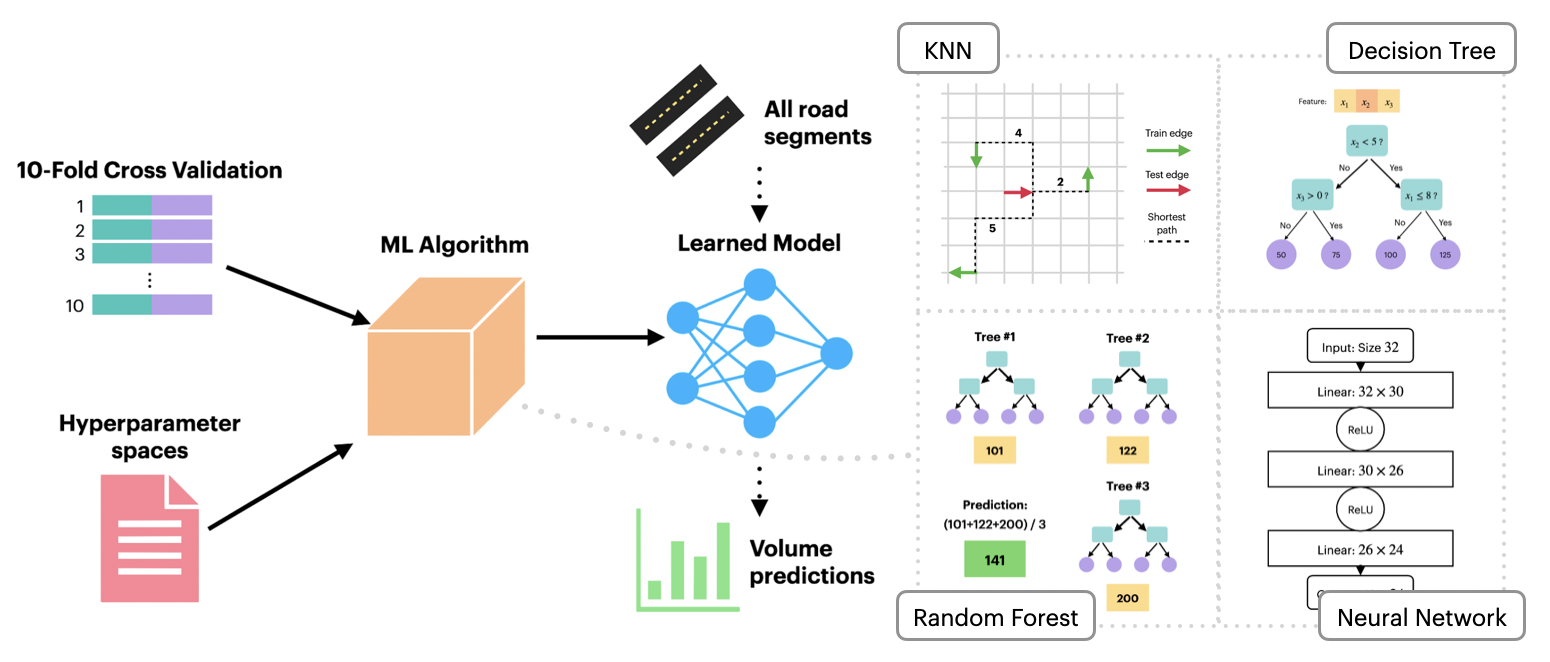
A Graph-Based Machine Learning Approach to Realistic Traffic Volume Generation 🚦 🏙
Machine Learning, Data Visualization, Statistical Analysis
In this work, we explore the potential for realistic and accurate generation of hourly traffic volume with machine learning (ML), using the ground-truth data of Manhattan road segments collected by the New York State Department of Transportation (NYSDOT). Specifically, we address the following question– can we develop a ML algorithm that generalizes the existing NYSDOT data to all road segments in Manhattan?– by introducing a supervised learning task of multi-output regression, where ML algorithms use road segment attributes to predict hourly traffic volume. We consider four ML algorithms– K-Nearest Neighbors, Decision Tree, Random Forest, and Neural Network– and hyperparameter tune by evaluating the performances of each algorithm with 10-fold cross validation. We also provide insight into the quantification of “trustworthiness” in a model, followed by brief discussions on interpreting model performance, suggesting potential project improvements, and identifying the biggest takeaways.
Paper · Presentation · Github
December 2021 - May 2022
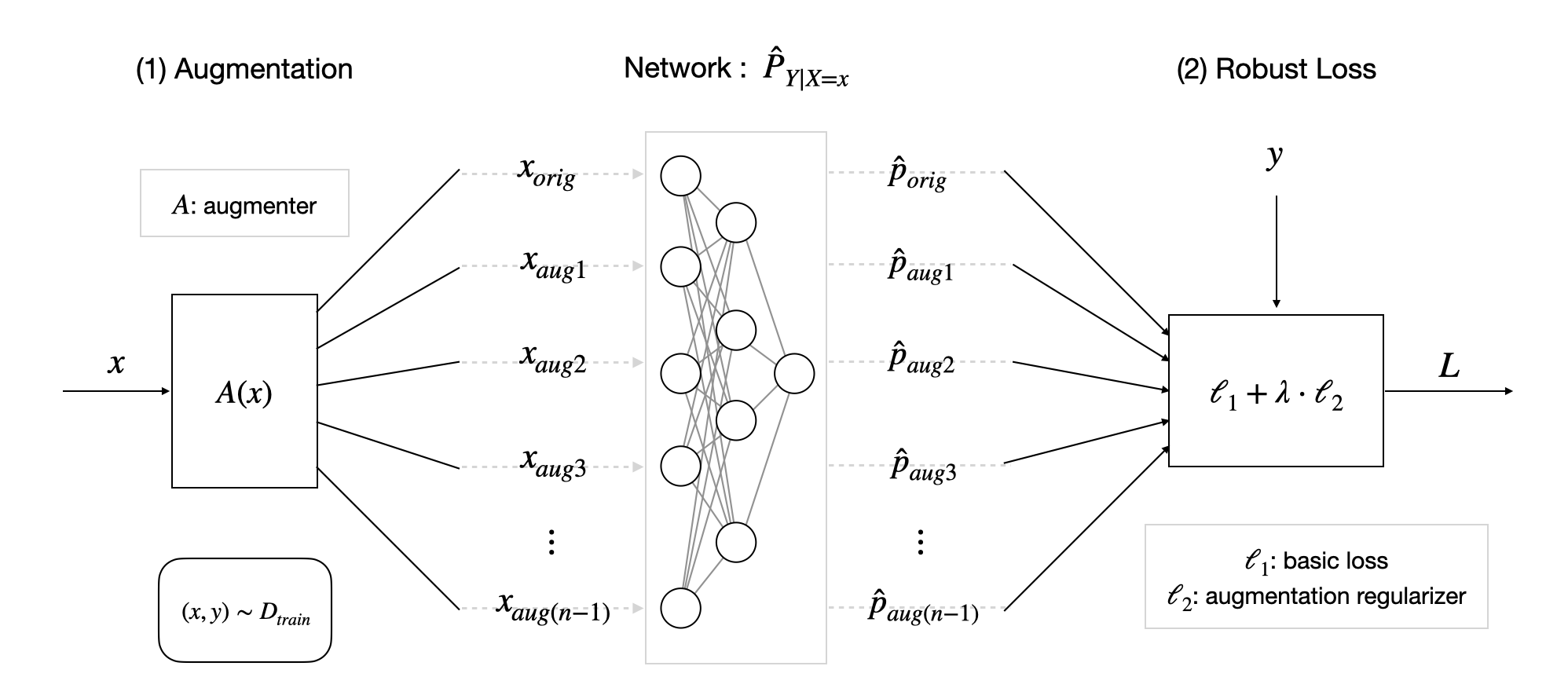
AugLoss: 🌦 🔍 A Learning Methodology for Real-World Dataset Corruption
Domain Adaptation, Robust Loss Functions, Data Augmentation
Deep learning models achieve great successes in many domains, but increasingly face safety and robustness concerns, including noisy labeling in the training stage and feature distribution shifts in the testing stage. Previous works made significant progress in addressing these problems, but the focus has
largely been on developing solutions for only one problem at a time. For
example, recent work has argued for the use of tunable robust loss functions to mitigate label noise, and data augmentation to
combat distribution shifts. As a step towards addressing both problems
simultaneously, we introduce AugLoss, a simple but effective methodology that achieves robustness against both train-time noisy labeling and
test-time feature distribution shifts by unifying data augmentation and
robust loss functions. We conduct comprehensive experiments in varied
settings of real-world dataset corruption to showcase the gains achieved
by AugLoss compared to previous state-of-the-art methods.
Paper · Presentation · Poster · Github
September 2021 - May 2022
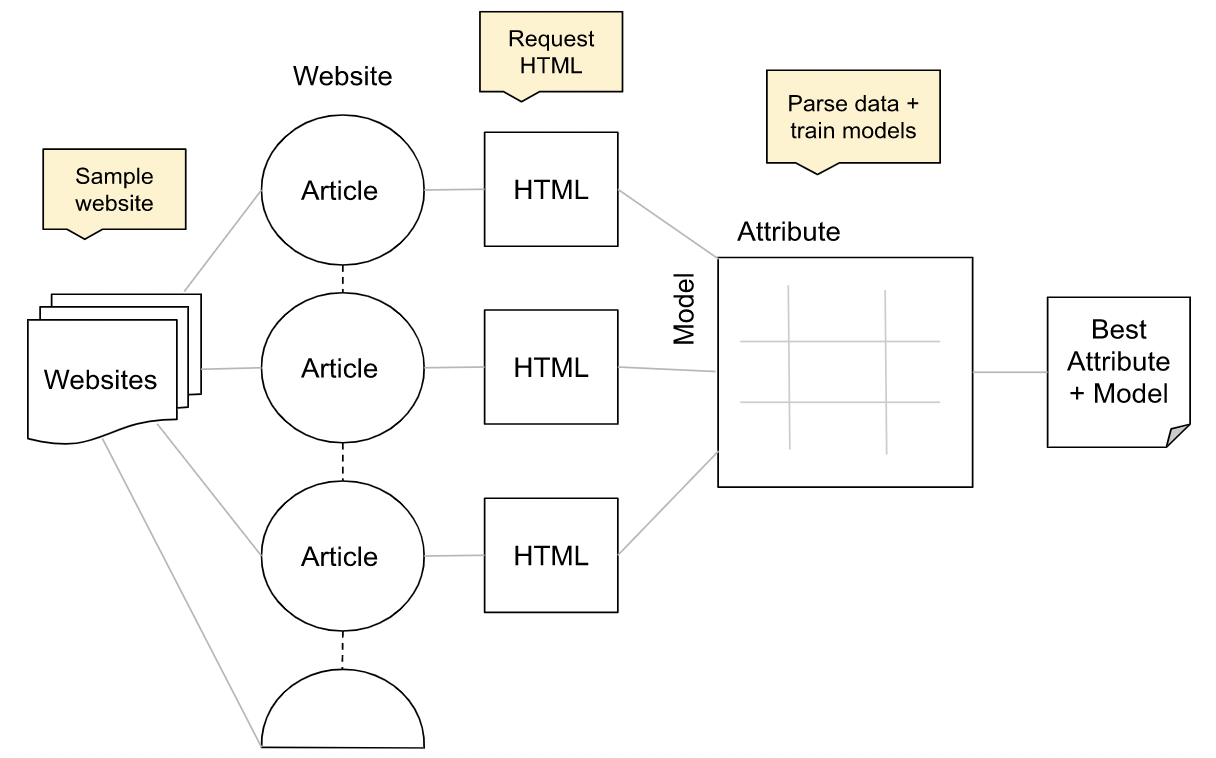
Building a Fact-Checked Article Classifier with Naive Bayes... and more! 🧐
Natural Language Processing, Web Scraping
In this project, I develop an original machine learning (ML) algorithm that classifies the conclusions of fact-checking articles (paired with other data, such as the topic, source, etc.) as one of the following labels: false, misleading, true, or unproven. I was provided with a train set of ~6,000 examples and an unlabeled test set of ~700 examples. My objective was to train a model on the train set and predict the labels of the examples in the test set, which would be evaluated for accuracy on Kaggle. The two major obstacles in the task were the heavy imbalance of labeling (mostly 0’s), and the need for feature engineering, as very little information was provided in the datasets. As a result, I was able to extract more features by requesting the HTML pages of each article in the dataset, then develop an algorithm (I call switching) that would primarily learn on these new features.
Report · Github
November 2021 - December 2021
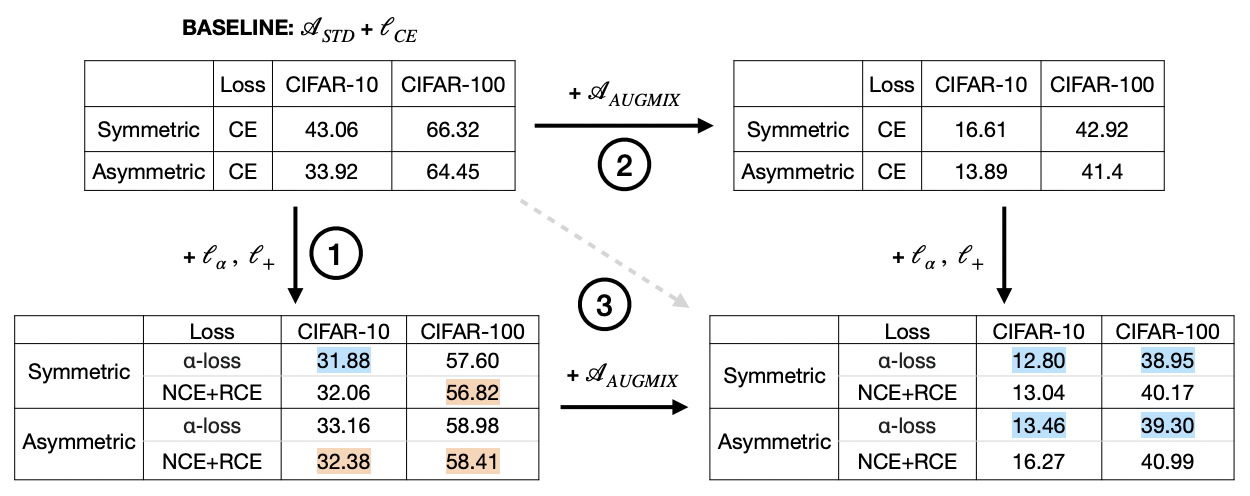
Robustness of a Tunable Loss Function Family on Corrupted Datasets 🏞 🔒
Image Classification, Robust Loss Functions, Data Augmentation
A very important assumption in image classification is that the train and test sets are independent and identically distributed (i.i.d.); when this assumption does not hold– whether on the prior (image distribution shift) or posterior (label noise) side– deep learning models noticeably decline in their performance. In this presentation, I discuss the use of two methods– data augmentation and robust loss functions– that address the problems of test-time
feature distribution shifts and train-time noisy labeling, respectively. Specifically, I demonstrate the effectiveness of AugLoss (a data augmentation technique) and alpha loss (a robust loss function) on corrupted versions of the CIFAR-10/100 datasets. Lastly, I combine the two methods and show that this combination achieves even better performance when both the test features and train labels are corrupted.
Presentation · Github
May 2021 - July 2021

Full-Stack Development of a Responsive Travel Blog AND Admin Portal 🛩 🌍
Web Development, Web Design
In this project, I designed and developed a travel blog + admin interface from scratch. The travel blog is fully responsive and features a variety of user-triggered animations, such as handwritten text, photos, and moving backgrounds.
The front end was implemented with HTML, CSS, and vanilla JavaScript. Additionally, the admin interface is password-protected and allows the blogger to post content (automatic image compression), manage the site layout, and send emails to subscribers; these back end features were primarily implemented with PHP.
Lastly, I used SQL with PHP MyAdmin to (1) create a newsletter database that collects subscribers’ names, emails, and other useful information, and (2) create an automated traffic monitoring service that allows the blogger to evaluate the performance of the site.
Website · Github
September 2020 - July 2021

Hypothetest: An interactive storyline generator for two-sample hypothesis tests ✏ 📈
Hypothesis Testing, Web Development
As a probability & statistics TA, I designed and developed a website that generates a customized write-up of the student's two-sample hypothesis test problem, including all calculation and explanation typically found in a statistics textbook. The design includes a simple but responsive layout, implemented with HTML and CSS. The functionality includes the navigation of a built-in storyboard, implemented with vanilla JavaScript. The MathJax JS library is used to generate the mathematical notation and equations, and the HighCharts JS library is used to dynamically graph the distributions.
Website · Github
November 2020 - December 2020